

Documentation
/ User's manual in C++
: 
| V.5. The artificial neural network | ||
|---|---|---|
 | Chapter V. The Modeler module |  |
Warning
This surrogate model, as implemented in Uranie, requires the Opt++ prerequisite (as discussed in Section I.1.2.2).
The Artificial Neural Networks (ANN) in Uranie are Multi Layer Perceptron
(MLP) with one or more hidden layer (containing 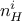 neurons, where
neurons, where 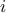 is use to identify the layer) and one or more output attribute. We can export them in ASCII file as "C", "Fortran" and
"PMML" formats to reuse them later on within Uranie or not.
is use to identify the layer) and one or more output attribute. We can export them in ASCII file as "C", "Fortran" and
"PMML" formats to reuse them later on within Uranie or not.
The artificial neural networks done within Uranie need input from OPT++ and can also benefit from the computation power of graphical process
unit (GPU) if available. Their implementation is done through the TANNModeler
Uranie-class, and their conception and
working flow is detailed in three steps in the following part, summarised in Figure V.3. For a thoroughly description of the artificial neural network, see [metho]
Figure V.3. Schematic description of the working flow of an artificial neural network as used in Uranie
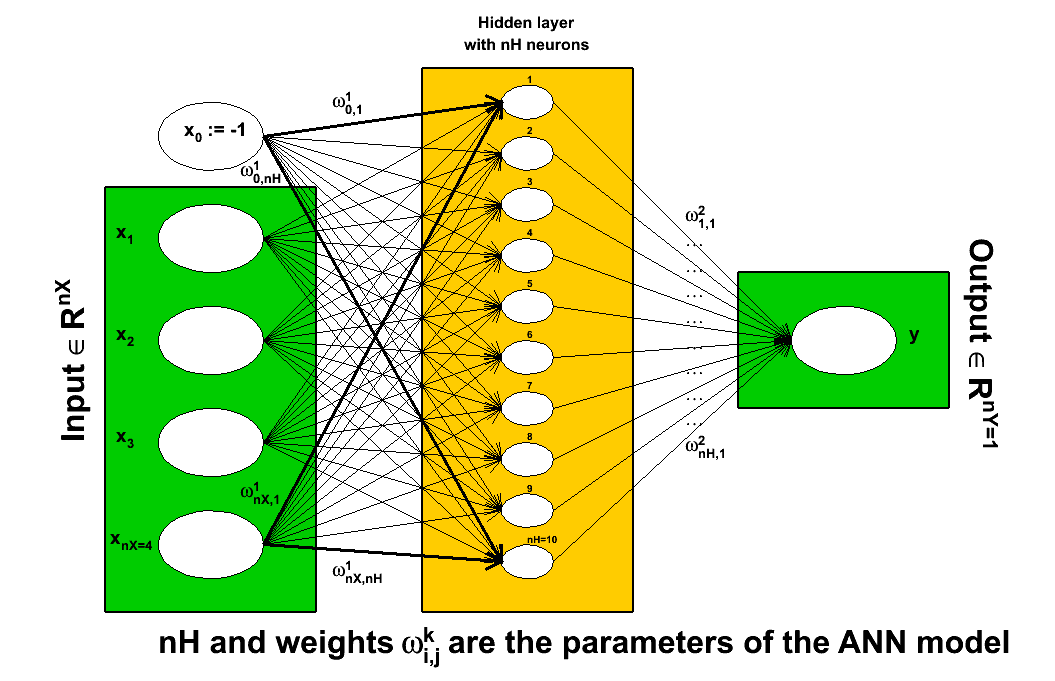 |
The first step is the creation of the artificial neural network in Uranie; there are several compulsory information that should be given at this stage:
a pointer to the
TDataServerobjectthe input variables to be used (as for the linear regression, it is perfectly possible to restrain to a certain number of inputs)
the number of neurons in the hidden layer
the name of the output variable
The three last information are gathered in a single string, using commas to separate clearly the different parts. This is further discussed in Section V.5.2.
The second step is the training of the ANN. Every formal neuron is a model that does not talk to any other neuron on the
considered hidden layer, and that is characterised by (taking, for illustration purpose, an index 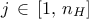 ):
):
the weight vector that affects it,
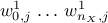 , using the
Figure V.3 (the superscript 1 stands for the layer
index, as there is only one hidden layer in Uranie implementation).
, using the
Figure V.3 (the superscript 1 stands for the layer
index, as there is only one hidden layer in Uranie implementation).an activation function
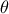 that goes along with the way the inputs and output are normalised.
that goes along with the way the inputs and output are normalised.
Combining these with the inputs give the internal state of the considered neuron, that is function of the weights' value, which are estimated from the training. To perform it, one can specify the tolerance parameter to stop the learning process (the default value being 1e-06). It is however necessary to give the number of times (a random permutation of) the test base will be presented for training and the number of times the ANN is trained (from random start weights) with a given permutation of the test database. The training session ends, keeping the best performance model obtained. This is further discussed in Section V.5.3 (and in [metho]).
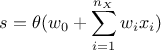
Finally, the constructed neural network can be (and should be) exported. Different format
are available to allow the user to plug the resulting function in its code whether it is using Uranie or not.
Warning
It is recommended to save the best estimated model, as running twice the same code will not give the same
results. There is indeed a stochastic part in the splitting of the training database that will induce differences
from one run to another.
The TANNModeler constructor is specified with a TDataServer which contains the input attributes and
the output attribute and with an integer to define the number of hidden neurons in the hidden layer. All these
information are stored in a string. These string is the second argument of the constructor.
TDataServer * tds = new TDataServer("tds","my TDS");
tds->fileDataRead("flowrate_sampler_launcher_500.dat");
TANNModeler* tann = new TANNModeler(tds, "rw:r:tu:tl:hu:hl:l:kw,4,yhat");In case one wants to use several hidden layer, the number of hidden neurons in each layer has to be specified in the architecture string, separated by commas. For example with three layers of 2, 3 and 4 neurons (dummy example for illustration purpose only), one would write something like this:
TANNModeler* tannML = new TANNModeler(tds, "rw:r:tu:tl:hu:hl:l:kw,2,3,4,yhat");
To split the data of the TDataServer in two databases, learning and test, we specify either a proportion (real value
between 0.0 and 1.0) of patterns or the number of patterns (integer greater than 2) to build the learning database.
The other patterns are stored in the test database. No validation base is explicitly created by Uranie.
The training and testing database split is done based on the ratio introduced in the
TANNModeler constructor, introduced previously. This is further discussed in [metho].
tann->setNormalization(TANNModeler::kMinusOneOne);
tann->setFcnTol(1e-8);
tann->train(3, 2, "test");| |  | |
| V.4. Adaptive development in polynomial chaos: the Anisp method |  | V.6. The kriging method |