

L'approche modulaire
La plateforme Uranie (v4.11.0) est basé sur ROOT (v6.32.04).
En conséquence, Uranie bénéficie de nombreuses caractéristiques de ROOT, parmi lesquelles :
- un interpréteur C++ interactif (Cling), construit sur LLVM et Clang;
- une interface Python (PyROOT);
- un accès à des bases de données SQL;
- de nombreuses fonctions avancées de visualisation de données;
- et bien plus encore...
Dans les sections suivantes, la plateforme ROOT sera brièvement présentée ainsi que l'interface Python pouvant etre utilisée une fois que les classes Uranie sont déclarées et connues. L'organisation de la plateforme Uranie est ensuite présentée, à grande échelle, introduisant les éléments nécessaires à la compréhension détaillée des éléments décrits dans la documentationd.
Dans la suite de cette section, chacun des modules abordés dans cette documentation sera brièvement décrit (leur rôle et leurs composants principaux). Une description plus précise est donnée dans les autres chapitres dédiés, en suivant les liens indiqués ci-dessous.
En conséquence, Uranie bénéficie de nombreuses caractéristiques de ROOT, parmi lesquelles :
- un interpréteur C++ interactif (Cling), construit sur LLVM et Clang;
- une interface Python (PyROOT);
- un accès à des bases de données SQL;
- de nombreuses fonctions avancées de visualisation de données;
- et bien plus encore...
Dans les sections suivantes, la plateforme ROOT sera brièvement présentée ainsi que l'interface Python pouvant etre utilisée une fois que les classes Uranie sont déclarées et connues. L'organisation de la plateforme Uranie est ensuite présentée, à grande échelle, introduisant les éléments nécessaires à la compréhension détaillée des éléments décrits dans la documentationd.
I. Modules d'organisation d'Uranie
La plateforme se compose d'un ensemble de bibliothèques techniques, ou modules (représentés par des boîtes vertes dans la figure I.1), chacun effectuant une tâche spécifique mais utilisés de manière interdépendante.Figure I.1. Organisation des modules Uranie (cases vertes) et leurs interdépendances. Les cases bleues représentent les dépendances externes.
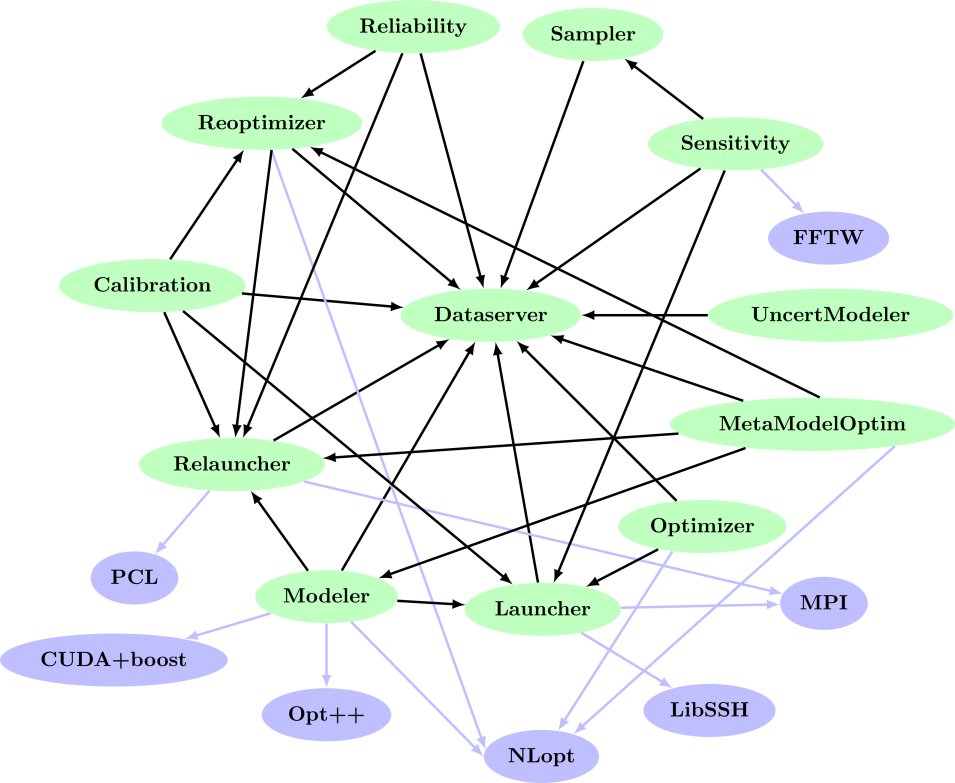
Dans la suite de cette section, chacun des modules abordés dans cette documentation sera brièvement décrit (leur rôle et leurs composants principaux). Une description plus précise est donnée dans les autres chapitres dédiés, en suivant les liens indiqués ci-dessous.