

Documentation
/ Manuel utilisateur en C++
: 
VIII.3. TEval | ||
|---|---|---|
 | Chapter VIII. The Relauncher module |  |
The TEval abstract class defines the interface of user evaluation model. It provides an user
class basis to define a model, and allows composition class to combine models together.
A standard evaluation is a function from 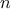 input parameters to
input parameters to 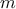 output parameters. and are known
and fixed during the run, but they can now be string, vectors, or double.
These evaluations may not return a value. Generally, it is due to an inconsistent input set.
output parameters. and are known
and fixed during the run, but they can now be string, vectors, or double.
These evaluations may not return a value. Generally, it is due to an inconsistent input set.
TMaster may support (or not) this lack.
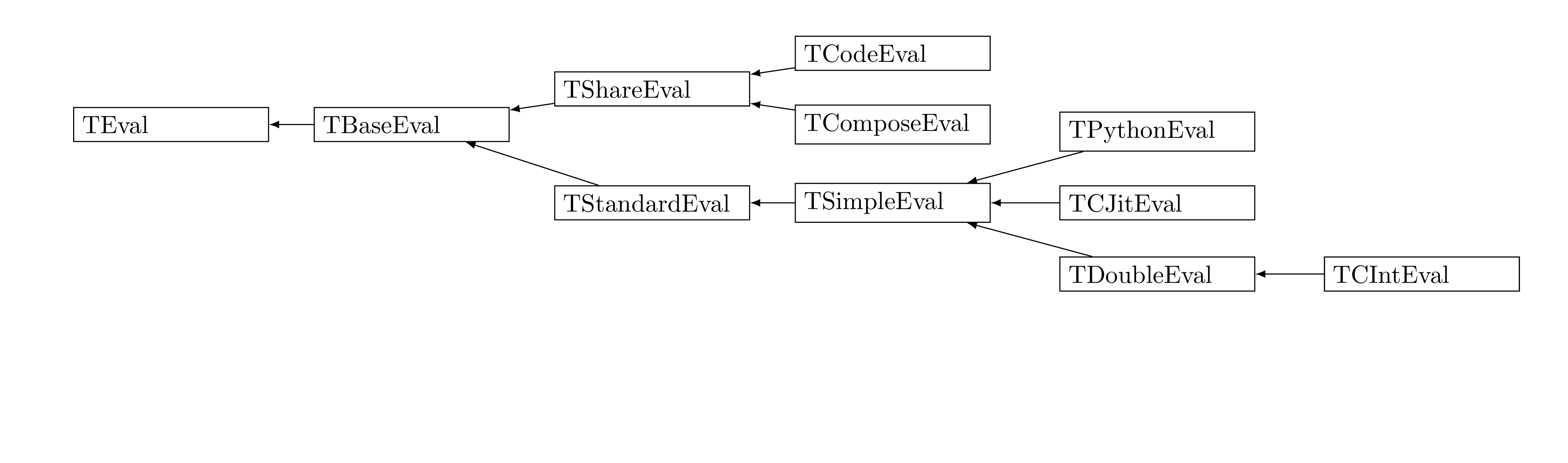
A glimpse of all the assessor classes available can be found in Figure VIII.2 that
displays the hierarchy of class starting from the inheritance of TEval.
Figure VIII.2. Hierarchy of classes and structures for the evaluation part of the Relauncher module.
 |
All the assessors will need to have attributes attached to them, both inputs and outputs. Input attributes might have a peculiar status, by being constant disregarding the provided stochastic law. On the other hand, output attributes might be considered temporary if, for instance, their value is of no interest for the final analysis but might be used by another assessor in composition. All this is discussed later on, in Section VIII.5 as these specification will be done directly on the master object.
These classes reify the TLauncherFunction analytic function.
The ROOT on-the-fly compiler is now compatible with the C++ syntax but there are two ways to access an already written functions:
with a pointer to the function directly (this function being properly compiled);
through the ROOT-register of function, passed as a string only;
For the former, whose interface is the TCJitEval class, only usable in C++, there are no
problem of thread-safety which is not the case for the latter, whose interface is the
TCIntEval class which is not considered thread-safe. Given these consideration the latter
shall not be used with a TThreadedRun, while the CJit version deals with the ROOT
Just in time compiler, and is considered thread-safe. This is further discussed in Section VIII.4.2.
User supplied function needs to comply with a C prototype. Both version class constructors can use the
TLauncherFunction prototype. Three extended prototypes are added for a more advanced usage.
// TLauncherFunction prototype
void standart_prototype(double *in, double *out);
// extension prototypes
int extended_prototype(double *in, double *out);
int extended_prototype(double *in, double *out, void *foo);
int uentry_prototype(std::vector<URANIE::DataServer::UEntry*> *in, std::vector<URANIE::DataServer::UEntry*> *out);The first extension is used to deal with non-calculable evaluations. It uses the return value, which should be 1 in usual case and 0 if the output values cannot be computed. The second one can be used to pass extra information to the function by casting it as a pointer of void. The last extension prototype is used when evaluation deals with string or std::vector<double> input or output. Its use is tricky so we recommend to contact us if this is the only solution you have.
The class constructor first argument is the function pointer.
TCJitEvalcan use standart and extended prototype and recognises it at compile time. This is the only runner able to deal with the complicated extended prototype.TCIntEvalcan use standart and extended prototype, but cannot recognise it (first argument is the function name as a string). It uses a second boolean argument to distinguish them. Default implicit value iskFALSEfor standart prototype (kTRUE for first extended prototype, void * value for second extended prototype.
The class definition gives information neither about the input or output number nor about parameter order.
These information have to be added to link with TDataServer and
TMaster definitions. We use the addInput and
addOutput method with TAttribute objects as argument to do so.
Inputs and outputs have to be added in correct order. Here is an example of how to precise inputs and outputs, from
the script in Section VIII.2:
// problem variables
TAttribute x("x", -3.0, 3.0),
y("y", -4., 6.),
ros("rose");
// user evaluation function
TCIntEval eval("rosenbrock");
eval.addInput(&x); // Adding attribute in the correct order
eval.addInput(&y);
eval.addOutput(&ros);
For a more user friendly definition, you can use the setInputs and
setOutputs methods. Instead of only requesting a pointer to the attribute under
consideration, a first compulsory argument is an integer that equals the number of attributes to come, followed by
as many pointers to attribute. Taking the example provided above, one can create a second assessor, using theses
methods instead of the addInput and addOutput ones.
// user evaluation function
TCIntEval eval2("rosenbrock");
eval2.setInputs(2,&x,&y); // Adding attributes in the correct order, all at once
eval2.setOutputs(1,&ros);
This class is used when you use Uranie with the python interpreter. So they are not detailed here.
More detail can be find in the python version of this documentation, but its use is very similar to a
TCJitEval class.
Its use with the C++ interpreter is not trivial (it needs to loads the python interpreter) and are not covered here.
Using a TCodeEval instead is a simpler solution.
This class takes up the TCode class features and make it thread safe.
Evaluation is done by an external executable, which reads one (or more) configuration file, where it finds its
inputs, and writes the single result file, where to find the output variables. TCodeEval must
create or adapt configuration files to introduce item values, run the executable, and analyse the result file to get
its outputs. It needs to know file formats, and where to find values.
In order to be used in parallel (MPI or thread), we have to take care of file access conflicts: many processes
which modify the same file. To avoid such a thing, Uranie creates for each resource a personal directory named
URA with then a set of numbers and letters that is more robust than the older version with just
increasing numbers. Everything is done in it: input files are created there, executable is run from it and the
output file are supposed to be found here as well. By default, these directories are created in the current
folder. You can specify another root directory, using the setWorkingDir method. There are
two other methods that can be called to change this:
setOldTmpDir(): This will create folder namedURANIE0, thenURANIE1and so on, up to the number of process chosen (for sequential job, onlyURANIE0will be created).keepAllFolders(): This method is meant for debugging. It creates a specific working directory for EVERY computations (warning it might overflow your home directory).
Input files are often created from template files. These files, if they are not defined with a full path, are search
in the current directory. You can specify another one using the setReference method.
The class constructor takes a string (const char*) as argument which is the command line used to
launch the executable. %D jocker can be used, and will be replaced by the local directory.
With the introduction of the vectors and strings from version 3.10.0, more complex interaction with files were introduced: how to differ two iterations of a single vector and how to differentiate a double from a string. This depends highly on the nature of the input/output file under consideration, whether it is just a text file used as database (in this case it depends mostly on the way you've written the code that generate/parse it) or whether it corresponds to a more strict kind of file, for instance a piece of code (c++/python/zsh). In the latter case, strings and vectors are not written in the same way. To take this into account, a rule has been defined (commonly to both input and output files, both in the Launcher and Relauncher module). There is a method for any kind of file to define properties of vector and string objects:
setVectorProperties(string beg, string delim, string end): the first element is the string beginning of the vector (usually "[" for python, "(" for zsh/sh, nothing...), the second one is the delimiter between iterators (usually "," for c++/python, blank for zsh/sh...) and the last one is the end of the string (usually the opposite character of the beginning one).setStringProperties(string beg, string end): the first and second elements are respectively the beginning and ending character used for string (oftenly """).
Depending on the kind of chosen file, there is a default configuration chosen. This default is precised in the following two sections.
Warning
The chosen output format has to be consistent with the output parameters investigated, particularly when some are vectors which can be empty for some specific configurations. In this peculiar but still possible case, the abscence of results is indeed a result of its own and should not be taken as a failure (from an incomplete output file for instance, this specific aspect being further discussed later-on in Section VIII.5.2.1).
Most of the time this would be independent of Uranie as it would be specific to the code under investigation, and as such, it might be tricky to handle. Two use-case macro have been written to show this, so please take a look at empty vectors considered as results in Section XIV.8.11 or considered as an error in Section XIV.8.12 only because of the way the output Key-format output file is written. In a nutshell, in the former case caution has been taken to properly delimit and condensate the results so that even when the vector is empty there are sign of this, while on the other hand a simple dump is done for every instance of the vector meaning that with no content, no dumping is done leading to Uranie stating that there might be missing information in this output file (once again this is discussed in Section VIII.5.2.1).
Input file formats supported by TCodeEval objects, include:
TFlatScript, Input file is created from scratch. Values are given in order separated by a blank separator. The default behaviour with respect to strings and vectors for this file, is to look like the DataServer format (from the Launcher module): strings have no specific beginning/ending characters, as for the vectors whose delimiter is chosen to be a comma.TLineScript, Input file is created from scratch. EachTAttributevalues are written on a specific line. Changing attribute means changing line. It is the equivalent of the Column format (from the Launcher module).TKeyScript, Input file is created from an original file. EachTAttributeis associated to a keyword. Values are substituted using a "keyword = value" pattern.TFlagScript, Input file is created from a template file. EachTAttributeis associated to a keyword. Each keyword is substituted directly by the current value.
TXmlScript is not provided in this version
The addInput method is used to declare parameters for all these file types. For
TFlatScript and TLineScript, it takes a single argument: a pointer to
a TAttribute object, while in the two other cases, the same first argument is completed by a
const char * for the key. The declaration order is only significant when no key is specified (so for
the TFlatScript and TLineScript files).
// Input File Flat format case
TFlatScript finp1("input_rosenbrock_with_values_rows.dat");
finp1.addInput(&x); // Adding attributes in the correct order, one-by-one
finp1.addInput(&y);
// Or Input File Key format case
TKeyScript kinp1("input_rosenbrock_with_keys.dat");
kinp1.addInput(&x, "x"); // Adding attributes in the correct order, one-by-one
kinp1.addInput(&y, "y");
A more condensed version of this addInput method exists for all these input types: the
setInputs method. Here as well, it takes an extra compulsory argument, an integer which
equals the number of attributes to come. The rest of the arguments are either a single pointer to a
TAttribute object for the TFlatScript and
TLineScript objects, or a pair composed of the same pointer directly followed by the key
(for the two other input file types). Starting back from our example written above, one could condensate this into
these lines:
// Input File Flat format case
TFlatScript finp2("input_rosenbrock_with_values_rows.dat");
finp2.setInputs(2, &x, &y); // Adding attributes in the correct order, all at once
// Or Input File Key format case
TKeyScript kinp2("input_rosenbrock_with_keys.dat");
kinp2.setInputs(2, &x, "x", &y, "y"); // Adding attributes in the correct order, all at once
Once done, the input files are provided to the TCodeEval object, using the
addInputFile method, as shown below:
// Add to the TCodeEval
TCodeEval code("rosenbrock -r"); // put "rosenbrock -k" instead for key
code.addInputFile(&finp1); // put &kinp1 instead for key
Output file formats supported by TCodeEval include:
TFlatResult, Output file is made up of an header characterised by # as first line character, and a line of floats separated by spaces. By default, it is constructed as the DataServer one (from Launcher module). One can consider using a flat output file written over several lines (so constructed as aTOutputFileRow) but one needs to be very careful about the fact that all attributes might not have the same number of entries (when dealing with vectors for instance). This is discussed in the third item of Section IV.3.1.2.3 and in Section XIV.4.32.1. To do this a specific method has to be calledisMultiLine(string separ)which says to the class that the results are written over many lines, and every field is separated by the stringsepar.TKeyResult, Value can be found on line composed with the key, a separator, the value and eventually a ; character. A separator is composed with space, tab, = and : characters.TLineResult. All the values of a givenTAttributeare written on a specific line. Changing attribute means changing line. It is the equivalent of the Column format (from the Launcher module).
TXmlResult is not provided in this version
In a similar way of TInputFile, one should use the addOutput to
declare parameters, the argument being the pointer to the attribute under consideration for all these formats,
pairing with the corresponding key when dealing with a TKeyResult object. This step can be
gathered in a single operation, as for the input file, using the setOutputs method. Here
is an example for the ongoing use-case.
// Input File Flat format case
TFlatResult fout("_output_rosenbrock_with_values_rows.dat");
fout.addOutput(&ros); // Or fout.setOutputs(1, &ros);
// Or Input File Key format case
TKeyResult kout("_output_rosenbrock_with_keys.dat");
kout.addOutput(&ros, "ros"); // Or kout.setOutputs(1, &ros);
Finally, use the addOutputFile method of TCodeEval to declare it:
// Add output file to the TCodeEval
code.addOutputFile(&fout); // put &kout instead for key
Composition offer the possibility to build an overall new kind of TEval from the succession of
many others. It defines an ordered sequence of evaluation functions. One important thing to notice is that
composition does not deal with distribution even if it is possible. It just applies sequentially all assessors and
become really helpfull as the output of an assessor at the i-Th rank can be used as input for the next assessor, the
(i+1)-Th one. This is one by creating a TComposeEval object as discussed briefly below.
This composer can be seen as an overall new assessor that is, usually provided to the runner (or to a master directly).
The constructor have no argument. The only important method is the addEval one that
allows users to add evaluation functions, keeping in mind that they should be called in the correct order,
regarding what they expect (the only argument of the function being a pointer to the assessor to be stacked to
create the chain). Examples of composition can be found in Section XIV.8.14.
As for the input/output attributes or a regular assessor, one can use the
setEvals (mind the "s") that allows to put all the pointers as argument of the function,
right after an int parameter that state the number of assessor procided to
define the composition.
| |  | |
| VIII.2. Relauncher abstraction levels |  | VIII.4. TRun |