

Documentation
/ User's manual in Python
: 
| IV.4. Distribution | ||
|---|---|---|
 | Chapter IV. The Launcher module |  |
To reduce elapsed time of computation, as the computations are independent, we can execute in parallel several of these computations; it is the computing distribution scheme.
In order to launch an Uranie script on a multi-core computer, the only modification to the code is the addition of
the parameter "localhost=X" to the run function of the Launcher object (where
X stands for the number of processors to use).
For example, the macro launchCodeFlowrateKeySampling.C can be launch on 5 processes with the following
run definition:
mylauncher.run("localhost=5")We can verify 5 processes are launched:
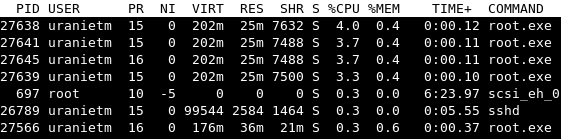
Uranie can also be launched on clusters with SLURM (curie at CCRT), LSF (tantale, platine at CCRT) or SGE (mars)
with BSUB directives. Moreover, the same macro of Uranie is used when launched in a
distributed mode or in a serial mode. It is only necessary to create a specific job file. It
is also possible to use batch clusters in order to run several instances of a parallel code, mixing two levels of
parallelism: one for the code, one for the design-of-experiments. This is achieved by specifying the number of
cores to be used per job with the setProcsPerJob(nbprocs) method of TLauncher.
mycodeSlurm = Launcher.TCode(tds, "flowrate -s -f")
foutSlurm = Launcher.TOutputFileKey("_output_flowrate_withKey_.dat")
mycodeSlurm.addOutputFile(foutSlurm)
mylauncherSlurm = Launcher.TLauncher(tds, mycodeSlurm)
mylauncherSlurm.setSave()
mylauncherSlurm.setClean()
mylauncherSlurm.setProcsPerJob(4)
mylauncherSlurm.setDrawProgressBar(False)
mylauncherSlurm.run()
This Uranie script excerpt will result in the execution of jobs with the command
where thecommand is the command to be typed to run the code under study (either
a root -l -q script.C or an executable if the code under consideration has been compiled).
An example of a job file is given below:
#BSUB -n 10  #BSUB -J FlowrateSampling
#BSUB -J FlowrateSampling  #BSUB -o FlowrateSampling.out
#BSUB -o FlowrateSampling.out  #BSUB -e FlowrateSampling.err
#BSUB -e FlowrateSampling.err  # Environement variables
# Environement variables  source uranie-platine.cshrc
# Clean the output file of bsub
rm -rf FlowrateSampling.out
# Launch the 1000 points of the design-of-experiments in 10 proc
root -l -q launchCodeFlowrateSampling.C
source uranie-platine.cshrc
# Clean the output file of bsub
rm -rf FlowrateSampling.out
# Launch the 1000 points of the design-of-experiments in 10 proc
root -l -q launchCodeFlowrateSampling.CExample of LSF cluster run
Define the number of processes to use, here 10. | |
Define the name of the job, FlowrateSampling | |
Name of the output file for the job. Warning
If the | |
Name of the error output file for the job. | |
All the lines following the BSUB instructions define the commands each node must run. |
Once the job file is created, it can be launch by using the command:
bsub < BSUB_File
where BSUB_FILE is the name of the file created below.
In order to see one's own jobs, run:
bjobsAn example of a job file is given below:
#$ -S /bin/csh
#$ -cwd
#$ -q express_par
#$ -N testFlowrate
#$ -l h_rt=00:55:00
#$ -pe openmpi 16  #####################################################
###### Cleaning
rm -f FlowrateFGA.*.log _flowrate_sampler_launcher_.* *~
#####################################################
###### Cleaning
rm -f FlowrateFGA.*.log _flowrate_sampler_launcher_.* *~  rm -fr URANIE
#####################################################
###### Execution
root -l -q launchCode.C
###### End Of File
rm -fr URANIE
#####################################################
###### Execution
root -l -q launchCode.C
###### End Of FileExample of SGE cluster run
Define the shell to use (here | |
Run the job from the current working directory. Allow to keep the environment variables defined. | |
Specify the queue to use (here | |
Name the job (here | |
Maximum time the job will last, in hh:mm:ss format. | |
All the lines following the QSUB instructions define the commands each node must run. | |
All the lines following the QSUB instructions define the commands each node must run. |
Once the job file is created, it can be launched by using the command:
qsub QSUB_FILE
where QSUB_FILE is the name of the previously-created file.
To see the running and pending jobs of the cluster, run the command:
qstatus -aIn order to see only one's own jobs:
qstatThe execution of large number of runs on a batch machine can sometimes require adjustments. The mechanism employed by Uranie relies on low-level mechanisms which are piloted from the ROOT process. This can lead to bottlenecks or performance degradation. Also, the execution of many processes at the same time can put a heavy burden on the file system. The following precautions should therefore be taken:
Standard output of the different processes should be kept at a reasonable level.
IO should be made as much as possible on the local disks.
When large number of processes run, the memory of the master node which runs jobs and also manages the execution can saturate. Uranie gives a possibility to dedicate this master node entirely to the execution management:
launcher->setEmptyMasterNode();When large number of processes (more than 500 for instance) run, they can terminate simultaneously and consequently the system has difficulties detecting the end of the jobs. It is useful to use a temporising mechanism provided by the
setDelay(nsec)method. This will make the last job startnsecseconds after the first one.
In order to distribute computation the TLauncher run method creates directories,
copies files, executes jobs and creates the output DataServer. All these operations are performed simultaneously, so
that it is possible to delete execution directories as the computation are performed (see the use of the
setSave(Int_t nb_save)).
However, it can be interesting to separate these operations when some of the runs fail or for batch systems. The
TLauncherByStep, inherited from TLauncher does just that: instead of the
run method, it has three methods which must be called sequentially:
preTreatment()which creates the directories and prepares the input files before execution,run(Option_t* option)which performs the execution of the code,postTreatment()which retrieves the information from the output files and fills theTDataserver.
The run method can be called with the following options:
option
"curie"will use the SLURM exclusive mechanism to perform the computation on the curie TGCC machine. In this case, unlike theTLaunchermechanism, the root script should be called directly on the interactive node, and the script will create the batch file and submit it.mycode = Launcher.TCode(tds, "flowrate -s -f") fout = Launcher.TOutputFileKey("_output_flowrate_withKey_.dat") mycode.addOutputFile(fout) mylauncherBS = Launcher.TLauncherByStep(tds, mycode) mylauncherBS.setSave() mylauncherBS.setClean() mylauncherBS.setProcsPerJob(4) mylauncherBS.preTreatment() mylauncherBS.setDrawProgressBar(False) mylauncherBS.run("curie")After the batch is completed, the assembly of the DataServer can be achieved by calling the
postTreatmentmethod.mylauncherBS.postTreatment()
This is a new way to distribute computation on one or several clusters. The idea is very specific to some specific running conditions, summarised below:
the cluster(s) must be reachable through ssh connections: Uranie has to be compiled, on the local machine you're working on, with a
libsshlibrary (whose version must be greater than 0.8.1).the code to be run has to be installed on the remote cluster(s) (with the same version, but this is up to the user to be sure of it).
the cluster(s) on which one wants to run, must be SLURM-based (so far that is the only solution implemented).
the job submission strategy of the cluster(s) have to allow the user to submit many jobs. The idea is indeed to run the estimations of the design-of-experiments by splitting in many jobs (up to one per locations) and send these jobs one by one through SSH tunneling in a given queue on the given cluster.
The main interesting consequence of this is that it allows to use clusters on which Uranie has not been installed on, as long as the user has an account and credential on it, an his code is accessible there as well.
Apart from the way the distribution is done, which is very specific and discussed below, it internal logic follows
the example provided in Section IV.4.4 as it can be used to split
the operations when some of the runs fail or for batch systems. The TLauncherByStepRemote indeed
inherits from TLauncher and it contains three methods which must be called sequentially:
preTreatment()which creates the directories and prepares the input files before execution,run(Option_t* option)which performs the execution of the code,postTreatment()which retrieves the information from the output files and fills theTDataserver.
The new steps are now discussed in the following subparts.
This generates and sends the scheduler a header file, produced thanks to a skeleton that is filled with information provided within the code and can be used by single and remote job submission. This skeleton will only differ depending on the scheduler used by the HPC platform that the user wants to use. It contains a set of common options that can be replaced within the macro file. The following file is an example
#!/bin/bash
################################################################
###################MARENOSTRUM 4 BASIC HEADER###################
################################################################
########################SLURM DIRECTIVES########################
# @filename@
#SBATCH -J @filename@
#SBATCH --qos=@queue@
#SBATCH -A @project@
#SBATCH -o @filename@.%j.out
#SBATCH -e @filename@.%j.err
#SBATCH -t @wallclock@
#SBATCH -n @numProcs@
###################END SLURM DIRECTIVES######################
source @configEnv@
Additionally, the user can edit that file to add additional options always following the variable nomenclature
@directive_name@. The skeleton will be handled internally by Uranie using the cluster configuration
defined by the user within the macro.
The next steps is to configure the launcher or launchers (as one can split the bunch of computations to be done by
creating several instances of TLauncherByStepRemote). In order to do this, a number of
function has been implemented such as:
tlch->setNumberOfChunks(Int_t numberofChunks): define the number of chunk;
tlch->setJobName(TString path): define the job name
The following lines are defining the compiling option as launchers can send code and compile it locally (new features for this remote launching): these following method will fill the
CMakeLists.txt.inthat is shown below.tlch->addCompilerDirective(TString directive, TString value): tlch->addCodeExternalLibrary(TString libName, TString libPath="" , TString includePath=""); tlch->addCodeLibrary(TString libName, TString sourcesList); tlch->addCodeDependency(TString destinationLib, TString sourceLibList);
tlch->run("nsplit=<all,n,[start-end]"):
The following skeleton is a CMake file used to compile code on the cluster if one wants to carry a piece of code from the workstation to the clusters.
#-------------------------------------------------------------------------
# Check if cmake has the required version
#-------------------------------------------------------------------------
cmake_minimum_required(VERSION 2.8.12)
PROJECT(@exe@ LANGUAGES C CXX)
if(COMMAND cmake_policy)
cmake_policy(SET CMP0003 NEW)
cmake_policy(SET CMP0002 OLD)
endif(COMMAND cmake_policy)
#---------------------------------------------------------------------------
# CMAKE_MODULE_PATH is used to:
# -define where are located the .cmake(which contains functions and macros)
# -define where are the external libraries or modules, third party()
#---------------------------------------------------------------------------
list(APPEND CMAKE_MODULE_PATH @workingDir@/CODE) # DON'T TOUCH
#-------------------------------------------------------------------------
# Compiler Generic Information for all projects
#-------------------------------------------------------------------------
set(CMAKE_VERBOSE_MAKEFILE FALSE)
if (CMAKE_COMPILER_IS_GNUCXX)
set(CMAKE_C_FLAGS_DEBUG "-g -ggdb -pg -fsanitize=undefined")
set(CMAKE_C_FLAGS_RELEASE "-O2")
set(CMAKE_CXX_FLAGS_DEBUG ${CMAKE_C_FLAGS_DEBUG})
set(CMAKE_CXX_FLAGS_RELEASE ${CMAKE_C_FLAGS_RELEASE})
endif ()
set(CMAKE_BUILD_TYPE RELEASE)
add_library(@exe@_compiler_flags INTERFACE)
target_compile_features(@exe@_compiler_flags INTERFACE cxx_std_11)
set(gcc_like_cxx "$<COMPILE_LANG_AND_ID:CXX,ARMClang,AppleClang,Clang,GNU>")
target_compile_options(@exe@_compiler_flags INTERFACE
"$<${gcc_like_cxx}:$<BUILD_INTERFACE:-Wall;-Wextra;-Wshadow;-Wformat=2;-Wunused>>"
)
#-------------------------------------------------------------------------
# Build shared libs ( if on libraries must be on remote )
#-------------------------------------------------------------------------
option(BUILD_SHARED_LIBS "Build using shared libraries" @sharedLibs@) #ON/OFF {default off}
#-------------------------------------------------------------------------
# Set OUTPUT PATH , it will be the working dir using URANIE TLAUNCHERREMOTE
# DO NOT CHANGE workingDir KEYWORD since it retrieves the info from TLauncherRemote->run();
# IF not changed, this will be sourceDirectory ( where you launch root) +/URANIE/JobName/
# Folders will make will be build and bin,
#-------------------------------------------------------------------------
set(CMAKE_BINARY_DIR @workingDir@)
set(EXECUTABLE_OUTPUT_PATH ${CMAKE_BINARY_DIR}/bin)
set(LIBRARY_OUTPUT_PATH ${CMAKE_BINARY_DIR}/lib)
#-------------------------------------------------------------------------
# Set Libraries
#-------------------------------------------------------------------------
# SET External LIBRARIES
#-------------------------------------------------------------------------
# Uranie cmake libraries are located on sources folder
#-------------------------------------------------------------------------
# ROOT
#include_directories(${ROOT_INCLUDE_DIR} ${INCLUDE_DIRECTORIES})
#URANIE
#URANIE_USE_PACKAGE(@workingDir@)
#URANIE_INCLUDE_DIRECTORIES(${LIBXML2_INCLUDE_DIR}
# ${ICONV_INCLUDE_DIR_WIN}
# )
@addExternalLibrary@
# User libraries
@addLibrary@
# add the executable
add_executable(@exe@ ${PROJECT_SOURCE_DIR}/CODE/@exe@)
#Link targets with their libs or libs with others libs
@addDependency@
The following piece o code shows an exemple of submitting script using the
TLauncherByStepRemote class.
#include "TLauncherByStepRemote.h"
#include <libssh/libssh.h>
#include <libssh/sftp.h>
#include <stdlib.h> //for using the function sleep
{
// =================================================================
// ======================== Classical code =========================
// =================================================================
//Number of samples
Int_t nS = 30;
// Define the DataServer
TDataServer *tds = new TDataServer("tdsflowrate", "DataBase flowrate");
// Add the eight attributes of the study with uniform law
tds->addAttribute( new TUniformDistribution("rw", 0.05, 0.15));
tds->addAttribute( new TUniformDistribution("r", 100.0, 50000.0));
tds->addAttribute( new TUniformDistribution("tu", 63070.0, 115600.0));
tds->addAttribute( new TUniformDistribution("tl", 63.1, 116.0));
tds->addAttribute( new TUniformDistribution("hu", 990.0, 1110.0));
tds->addAttribute( new TUniformDistribution("hl", 700.0, 820.0));
tds->addAttribute( new TUniformDistribution("l", 1120.0, 1680.0));
tds->addAttribute( new TUniformDistribution("kw", 9855.0, 12045.0));
// Handle a file with flags, usual method
TString sFileName = TString("flowrate_input_with_flags.in");
tds->getAttribute("rw")->setFileFlag(sFileName, "@Rw@");
tds->getAttribute("r")->setFileFlag(sFileName, "@R@");
tds->getAttribute("tu")->setFileFlag(sFileName, "@Tu@");
tds->getAttribute("tl")->setFileFlag(sFileName, "@Tl@");
tds->getAttribute("hu")->setFileFlag(sFileName, "@Hu@");
tds->getAttribute("hl")->setFileFlag(sFileName, "@Hl@");
tds->getAttribute("l")->setFileFlag(sFileName, "@L@");
tds->getAttribute("kw")->setFileFlag(sFileName, "@Kw@");
// Create a basic doe
TSampling *sampling = new TSampling(tds, "lhs", nS);
sampling->generateSample();
// Define the code with command line....
TCode *mycode = new TCode(tds, "flowrate -s -f ");
// ... and output attribute and file
TAttribute * tyhat = new TAttribute("yhat");
tyhat->setDefaultValue(-200.0);
fout->addAttribute(tyhat);
TOutputFileRow *fout = new TOutputFileRow("_output_flowrate_withRow_.dat");
mycode->addOutputFile( fout );
// =================================================================
// ================== Specific remote code =========================
// =================================================================
// Create the remote launcher, the third argument is the type of cluster to be used.
TLauncherByStepRemote *tlch = new TLauncherByStepRemote(tds, mycode,TLauncherByStepRemote::EDistrib::kSLURM);
// Provide the name of the cluster
tlch->getCluster()->setCluster("marenostrum4");
// Define the header file
tlch->getCluster()->setOutputHeaderName("a1.sh");
tlch->getCluster()->selectHeader("mn4_slurm_skeleton.in");
tlch->getCluster()->setRemotePath("./multiTestSingle");
tlch->getCluster()->addClusterDirective("filename"," multiTestSingle");
tlch->getCluster()->addClusterDirective("queue","debug");
tlch->getCluster()->addClusterDirective("project","[...]"); //Earth
tlch->getCluster()->addClusterDirective("numProcs","1");
tlch->getCluster()->addClusterDirective("wallclock","5:00");
tlch->getCluster()->setNumberOfCores(1);
tlch->getCluster()->addClusterDirective("configEnv","/home/[...]");
// Define the username and authentification method chosen
tlch->getCluster()->setClusterUserAuth("login","public_key");
//END OF SLURM SCRIPT
tlch->setClean();
tlch->setSave();
tlch->setVarDraw("hu:hl","yhat>0","");
/////////////////////
tlch->setNumberOfChunks(5);
tlch->setJobName("job3_tlch1");
tlch->run();
//tlch->run("nsplit=[0-1]");
//tlch->run("nsplit=0");
//tlch->run("nsplit=1");
//tlch->run("nsplit=[2-3]");
//tlch->run("nsplit=[3-5]");
//tlch->run("nsplit=all");
//tlch->run(); //simultaneous,nonblocking
tlch->postTreatment();
//SOME RESULTS
tds->exportData("_output_flowrate_withRow_.dat","rw:r:tu:tl:hu:hl:l:kw:yhat");
tds->draw("rw:r:tu:tl:hu:hl:l:kw:yhat","","para");
}
| |  | |
| IV.3. External Code |  | Chapter V. The Modeler module |