

The modular approach
Uranie (the version under discussion here being v4.11.0) is a software dedicated to perform studies on uncertainty propagation, sensitivity analysis and surrogate model generation and calibration, based on ROOT (the corresponding version being v6.32.04).
As a result, Uranie benefits from numerous features of ROOT, among which:
- an interactive C++ interpreter (Cling), built on the top of LLVM and Clang;
- a Python interface (PyROOT);
- an access to SQL databases;
- many advanced data visualisation features;
- and much more...
In the following sections, the ROOT platform will be briefly introduced as well as the python interface it brings once the Uranie classes are declared and known. The organisation of the Uranie platform is then introduced, from a broad scale, giving access to more refined discussion within this documentation.
Dans la suite de cette section, chacun des modules abordés dans cette documentation sera brièvement décrit (leur rôle et leurs composants principaux). Une description plus précise est donnée dans les autres chapitres dédiés, en suivant les liens indiqués ci-dessous.
As a result, Uranie benefits from numerous features of ROOT, among which:
- an interactive C++ interpreter (Cling), built on the top of LLVM and Clang;
- a Python interface (PyROOT);
- an access to SQL databases;
- many advanced data visualisation features;
- and much more...
In the following sections, the ROOT platform will be briefly introduced as well as the python interface it brings once the Uranie classes are declared and known. The organisation of the Uranie platform is then introduced, from a broad scale, giving access to more refined discussion within this documentation.
I. Uranie modules organisation
The platform consists of a set of so-called technical libraries, or modules (represented as green boxes in Figure I.1), each performing a specific task.Figure I.1. Organisation of the Uranie-modules (green boxes) in terms of inter-dependencies. The blue boxes represent the external dependencies (discussed later on).
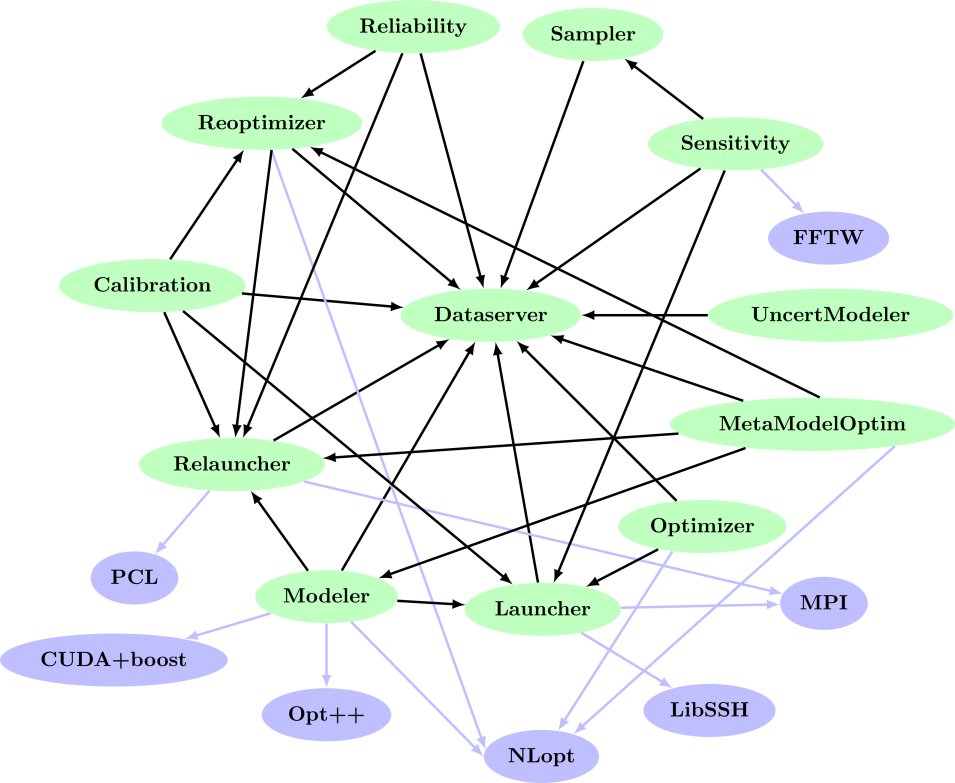
Dans la suite de cette section, chacun des modules abordés dans cette documentation sera brièvement décrit (leur rôle et leurs composants principaux). Une description plus précise est donnée dans les autres chapitres dédiés, en suivant les liens indiqués ci-dessous.